How to Classify PDFs in n8n ? A simple 3-Node Workflow to Auto-Route Invoices, Contracts & Receipts !
You get a mix of PDFs—invoices, contracts, receipts—and you need them sorted by type so the right workflow handles each one. Doing that by hand doesn't scale.
The fix: Define your classification rules on dev.pdf4me.com (using regex or JavaScript expressions), then run the same classification inside n8n: download a PDF (e.g. from Dropbox) → PDF4me Classify Document → use the returned className to route or organize. Classification lives in your PDF4me account; n8n just sends the file and gets back the class.
This guide has two parts. Part 1 is on dev.pdf4me.com: where to go and how to set up your first class (e.g. pdf4me_invoice with a regex like invoice(.*)). Part 2 is on n8n: a three-node workflow (Trigger → Download a file → Classify document) and how to read the result. All steps and screenshots are fact-checked from the PDF4me and n8n UIs.
What You Need
- A PDF4me account — Sign in at PDF4me. Classification templates are created and stored in your account at Classify Document. You define expressions in regex or JavaScript (for AI-based classification, custom training can be arranged—contact PDF4me if needed).
- n8n — Self-hosted or n8n Cloud. Add the PDF4me and Dropbox nodes.
- A PDF4me API key — Get your PDF4me API key. In n8n, create a PDF4me credential. First time? See Connect PDF4me to n8n.
- A file source — We use Dropbox – Download a file so the steps match our screenshots. You can use Google Drive, HTTP Request, or any node that supplies binary PDF data. The flow stays the same: get the PDF → Classify document → use className in the next node.
Part 1: Set Up Classification on dev.pdf4me.com
Classification is defined and stored on dev.pdf4me.com. You create document classes and assign each class an expression (regex or JavaScript). When you call Classify Document from n8n, PDF4me uses these templates to return a Class Name (exposed as className in the output) for the PDF you send. Do this part first so your n8n workflow has something to run against.
Step 1: Open Classify Document on PDF4me
- Log in at PDF4me (dev.pdf4me.com).
- In the sidebar, click Classify Document. The page title is Classify Document and the subtitle is Classify your documents based on expressions.
Step 2: Create or Edit a Class
- On the Classify Document page, click the blue Edit button (with the pencil icon) to create a new classification template or modify an existing one.
- You'll see the class definition area where you can add document classes and define how each is matched.

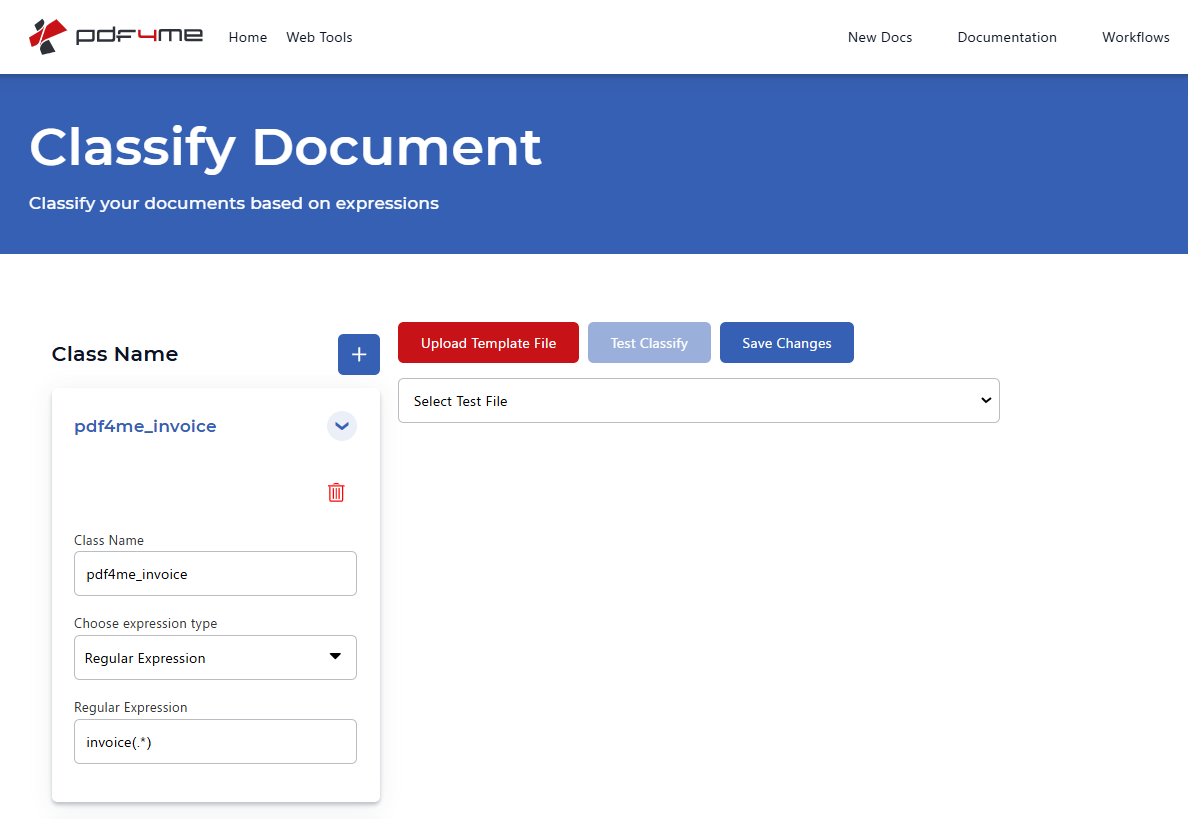
Step 3: Define a Class Name and Expression
- Under Class Name, click the + (plus) button to add a new class if needed.
- In the class card:
- Class Name — Give the class a name that will be returned by the API (e.g.
pdf4me_invoice). This is the value you'll see as className in the n8n Classify document output. - Choose expression type — Select Regular Expression or JavaScript depending on how you want to match the document content.
- Regular Expression (if you chose regex) — Enter a pattern that identifies this document type. Example:
invoice(.*)to match documents containing the word "invoice" followed by any characters.
- Class Name — Give the class a name that will be returned by the API (e.g.
- Use Select Test File to pick a file, then click Test Classify to see which class it matches.
- Click Save Changes so the classes are saved to your PDF4me account. These are the templates that the n8n Classify document node will use.
Important: Classification on PDF4me uses expressions in regex or JavaScript. The guideline and UI are at Classify Document on PDF4me. For AI-based classification with custom training, PDF4me can schedule a call to help.
Part 2: Automate Classification in n8n
Once your classes exist on dev.pdf4me.com, you can run classification from n8n: get a PDF from a previous node (e.g. Dropbox) and send it to PDF4me – Classify document. The node returns className (e.g. pdf4me_invoice), which you can use for routing, renaming, or further steps.
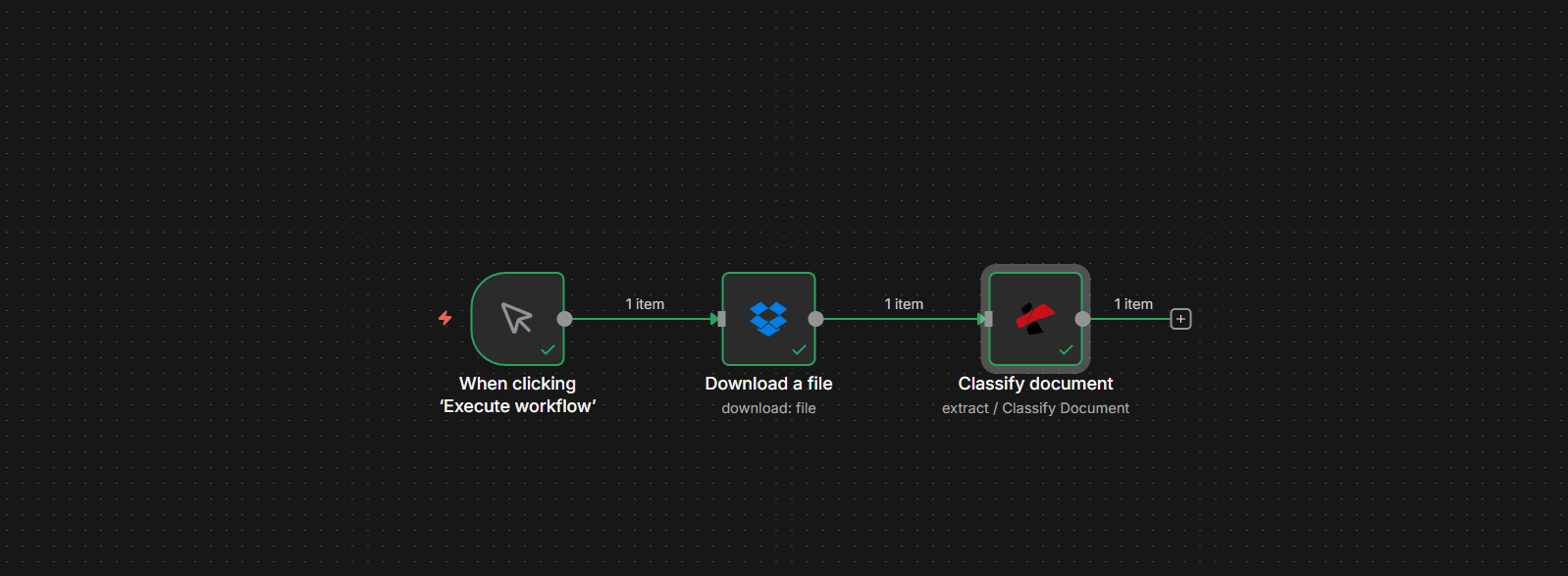
The Workflow at a Glance
Your n8n workflow has three nodes (screenshot below—all show a green checkmark when executed):
- When clicking 'Execute workflow' — Manual trigger for testing. For production, use When a file is created (Dropbox), Webhook, or another trigger.
- Download a file (Dropbox) — Retrieves the PDF from a path you specify (e.g.
/pdf4metest/ClassifyDocs/invoice_Pdf4me-202503-25041.pdf). Puts the file in a binary field (e.g.data). - Classify document (PDF4me) — Sends that PDF to PDF4me using your saved classification templates. Output: className (e.g.
pdf4me_invoice). Full details: Classify Document — n8n.
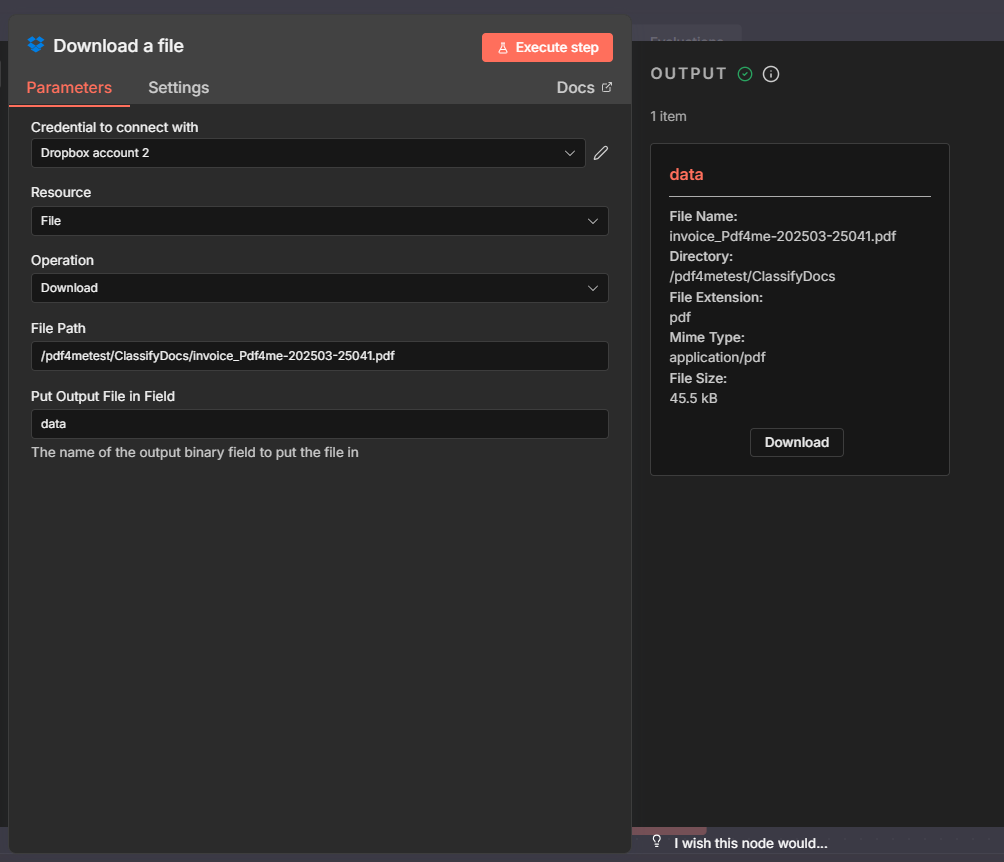
Step 1: Download a File (Dropbox)
Get the PDF into n8n so the next node can send it to PDF4me. The binary content is stored in a field (e.g. data) that the Classify document node will use.
Flow so far: Trigger → Download a file.
- Add a trigger — e.g. When clicking 'Execute workflow' for testing. For production, use Dropbox – When a file is created or another trigger.
- Add Dropbox → Download a file.
- Credential to connect with — Choose your Dropbox credential (e.g. Dropbox account 2).
- Resource — File.
- Operation — Download.
- File Path * — Enter the full path to your PDF. In our screenshot:
/pdf4metest/ClassifyDocs/invoice_Pdf4me-202503-25041.pdf. - Put Output File in Field — Set to
data(or another name). This is the binary field name the Classify document node will reference. The output will include File Name, Directory, File Extension, Mime Type, and File Size. - Execute step to test. The output shows the downloaded file metadata (e.g. File Name:
invoice_Pdf4me-202503-25041.pdf, Mime Type:application/pdf, File Size:45.5 kB).
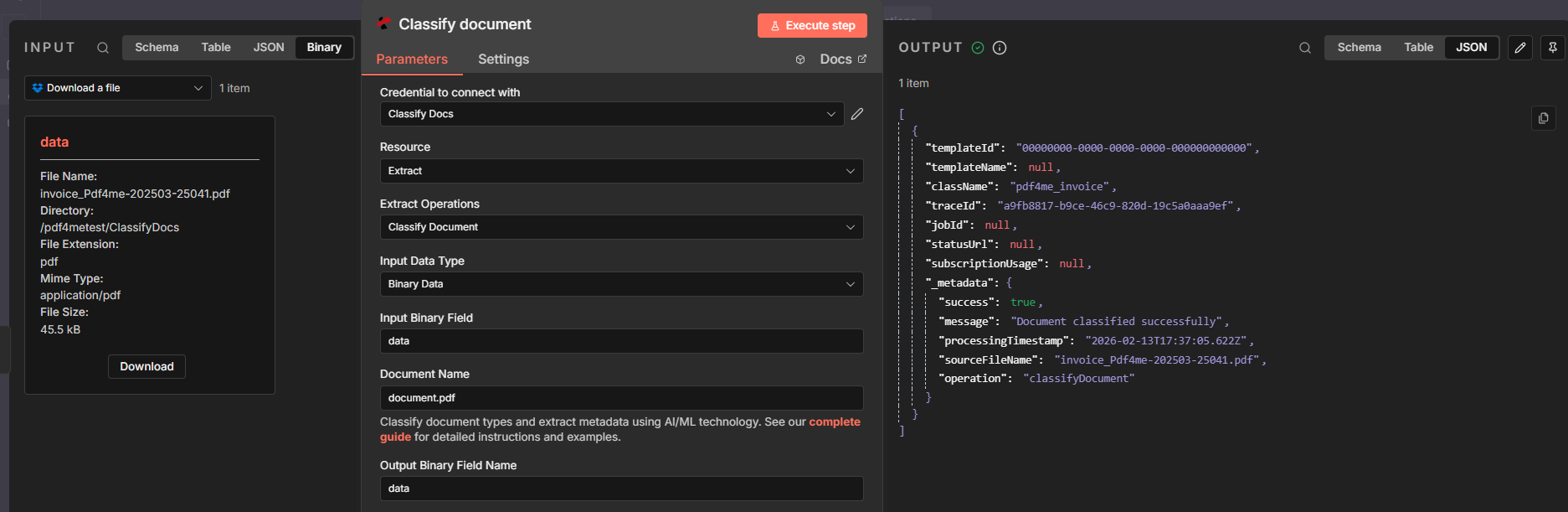
Step 2: Classify document (PDF4me)
Send the downloaded PDF to PDF4me. Classification uses the templates you defined in Part 1 on dev.pdf4me.com.
Flow so far: Download a file → Classify document.
- Add PDF4me → Classify document (under Extract).
- Credential to connect with — Choose your PDF4me credential (e.g. Classify Docs). Create one with your API key if needed.
- Resource — Extract.
- Extract Operations — Classify Document.
- Input Data Type — Binary Data.
- Input Binary Field — Set to
data(the same field name you used in the Download a file node). This tells the node to use the binary PDF from the previous step. - Document Name — Optional. Enter a reference name (e.g.
document.pdf) for tracking. You can also use an expression like{{ $json.fileName }}from the Download node. - Output Binary Field Name — Optional. Default is
data; you can leave as is or change if needed. - Execute step to test. The output includes className (e.g.
pdf4me_invoice), templateId, traceId, and _metadata (e.g.success: true,message: "Document classified successfully",sourceFileName).
Step 3: Use the Result
The Classify document output includes className (e.g. pdf4me_invoice). In subsequent nodes you can use this value to route the document—for example, add an IF node and branch on {{ $json.className }}. Use Switch to route to different paths (invoices, contracts, receipts), or pass className to an Upload node to save the file with a type-prefixed name. Each classification uses 1 credit.
Key Takeaways
How It Works
- Classification is defined on dev.pdf4me.com. Go to Classify Document in the PDF4me sidebar, use Edit, and add classes with regex or JavaScript expressions. Save your changes so n8n can use these templates.
- n8n only runs the classification. Download a PDF (e.g. from Dropbox) and pass its binary field (data) to PDF4me – Classify document. The node returns className (e.g.
pdf4me_invoice) so you can route or organize in later nodes. - One credit per classification. Each Classify document operation uses 1 credit. Use the className output in IF, Switch, or follow-up nodes.
- For AI-based classification with custom training, PDF4me can help—reach out to schedule a call. For regex/JavaScript setup, use the Classify Document page and this guide.
Real-World Use Cases
Add classification templates in your PDF4me account, then use them in n8n to route, rename, or trigger type-specific workflows:
Route invoices vs contracts to different folders
Problem: Mixed PDFs land in one Dropbox folder; invoices go to accounting, contracts go to legal.
Solution: Define classes on PDF4me (e.g. invoice, contract). In n8n, add an IF or Switch node after Classify document: if className = invoice, upload to /Accounting/Invoices/; if contract, upload to /Legal/Contracts/.
Parse by document type (different templates per class)
Problem: Invoices need one parse template; receipts need another. You don't know which until you know the type.
Solution: Classify first, then parse. Add classes on PDF4me (e.g. invoice, receipt). In n8n: Download a file, Classify document, Switch on className. For invoice, add Parse Document with the invoice template; for receipt, add Parse Document with the receipt template.
Rename files by class for search and filing
Problem: Generic filenames like document.pdf; you want to prefix the class (e.g. invoice_document.pdf, contract_document.pdf).
Solution: Add classes on PDF4me, then in n8n: Download a file, Classify document, Upload (Dropbox, Google Drive, etc.). Set File Path or File Name using an expression: {{ $json.className }}_{{ $('Download a file').item.json.fileName }}.
Next Steps
- Set up classes on PDF4me — Open Classify Document, click Edit, add a class (e.g.
pdf4me_invoice) with a Regular Expression or JavaScript expression, then Save Changes. - Get an API key — PDF4me API key dashboard. Use it in n8n to create your PDF4me credential.
- New to PDF4me + n8n? — Connect PDF4me to n8n shows how to create the credential.
- Build the workflow — Trigger → Download a file (Dropbox) → Classify document. Set Input Binary Field to the output field from Download (e.g.
data); use className in the next node. - Full node reference — Classify Document — n8n for all parameters and output fields.