HTML File in Dropbox or SharePoint? Power Automate Converts It to PDF. Three Actions, That's It!
You have HTML sitting in Dropbox, SharePoint, or OneDrive. You need a PDF for email, archiving, or sharing. Manually printing to PDF does not scale. Power Automate plus PDF4me turns HTML into PDF in three actions: get the file content, run Convert HTML to PDF, and create the file in your folder. No code. Works with Microsoft 365 and cloud storage. Connect, map the file, and get a ready-to-use PDF.
In a nutshell: Get file content using path (e.g. /blog data/html/sample.html) → PDF4me – Convert HTML to PDF (map File Content from Get file, HTML File Name with .html, Layout Portrait or Landscape) → Create file. Output: PDF ready to store, email, or pass to the next action.
Why-Based Q&A
Why use Power Automate for HTML to PDF? Power Automate integrates with Microsoft 365, Dropbox, SharePoint, and OneDrive. When HTML lives in a folder, a flow can get it, convert to PDF, and save the result. Ideal for reports, invoices, and certificates without leaving the Microsoft ecosystem.
Why map File Content from Get file content? Convert HTML to PDF needs the actual file bytes. Map File Content from the Get file content action so Power Automate passes the binary to PDF4me, not the path or metadata.
Why PDF4me Convert HTML to PDF? The action preserves CSS, images, and layout. You get Portrait or Landscape control and direct output for Create file. No extra steps when the file is already in your flow.
What You'll Get
Input: An HTML file in Dropbox, SharePoint, or OneDrive (e.g. sample.html). Output: A PDF file ready to upload, email, or pass to the next action.
What You Need
- Power Automate — Open Power Automate. Create a new cloud flow (Instant or Automated).
- PDF4me API key — Get your API key. Connect it when you add the PDF4me action. First time? See Connect PDF4me to Power Automate.
- Dropbox, SharePoint, or OneDrive — For the HTML file and output PDF folder. Use the connector that matches your storage.
The Flow at a Glance
- Manually trigger a flow (or When a file is created for automation).
- Get file content using path (Dropbox or SharePoint) — Fetches the HTML file from a path.
- PDF4me – Convert HTML to PDF — Converts the HTML to PDF. Map File Content from Get file content, set HTML File Name (with .html), and Layout.
- Create file (Dropbox or SharePoint) — Saves the PDF to your output folder.
Complete flow overview
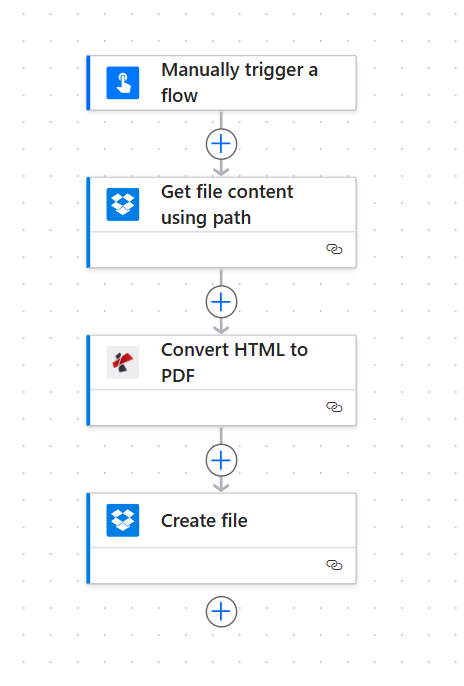
Four steps in sequence: Trigger, Get file content, Convert HTML to PDF, Create file. Each action shows a green checkmark when configured. The file from Get file content is passed into PDF4me, and the PDF output is saved via Create file.
Step 1: Get the HTML File
Flow so far: Trigger and Get file content only.
- Add Manually trigger a flow (or When a file is created in Dropbox or SharePoint for automation).
- Add Dropbox (or SharePoint) → Get file content using path.
- File Path — Enter the path to your HTML file, e.g.
/blog data/html/sample.html. - Infer content type — Yes (optional).
- Run the action to confirm the file is retrieved. The output File Content will be passed to PDF4me.
Get file content using path: Configuration
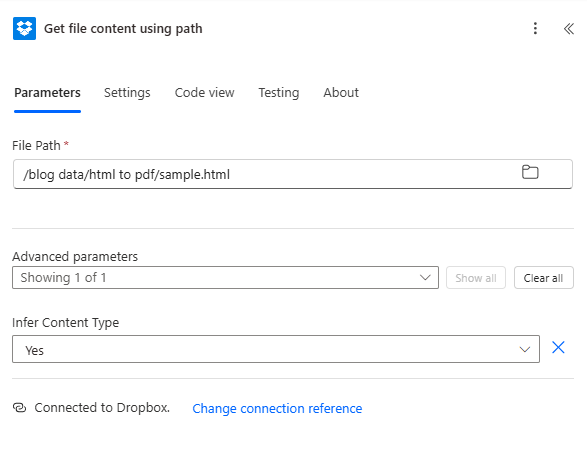
Get file content: File Path set to the HTML location. The output File Content (binary) is passed to the Convert HTML to PDF action. Use dynamic content for automation when a new file is created.
Step 2: Convert HTML to PDF
Flow so far: Get file content → Convert HTML to PDF.
- Add PDF4me → Convert HTML to PDF (or HTML to PDF).
- File Content — Map File Content from the Get file content action.
- HTML File Name — The HTML filename with extension, e.g.
sample.html. Must include.htmlso PDF4me detects the format. - Layout — Portrait or Landscape.
- Connect your PDF4me account if prompted.
- Run the action to test. PDF4me returns File Content (the PDF binary).
PDF4me – Convert HTML to PDF: File and layout
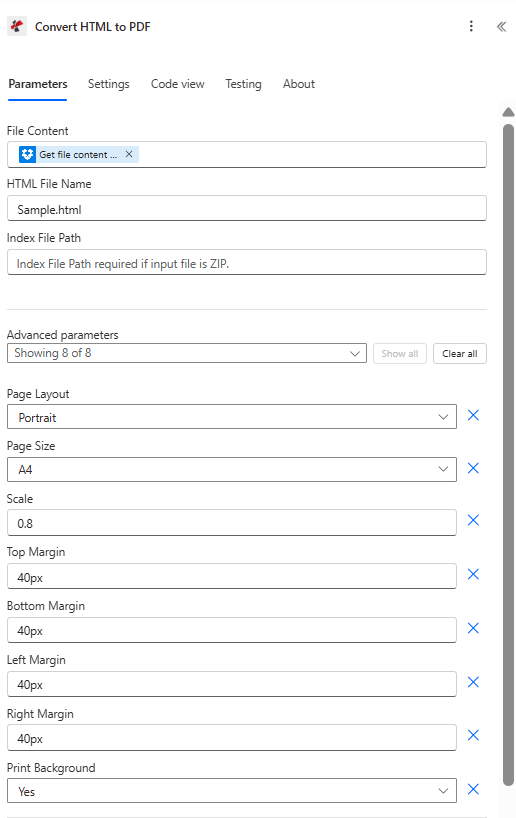
Convert HTML to PDF: File Content mapped from Get file content, HTML File Name with .html extension, Layout set to Portrait or Landscape. PDF4me preserves CSS and images from the HTML.
Step 3: Create the File (Save the PDF)
Flow so far: Get file content → Convert HTML to PDF → Create file.
- Add Dropbox (or SharePoint) → Create file.
- Folder Path — Enter the output path, e.g.
/blog data/html/output. - File Name — e.g.
output.pdfor map from the Convert action output. - File Content — Map File Content from the PDF4me Convert HTML to PDF action (not from Get file content; that is the original HTML).
- Run the flow. The PDF is saved to your folder.
Create file: Save PDF to output folder
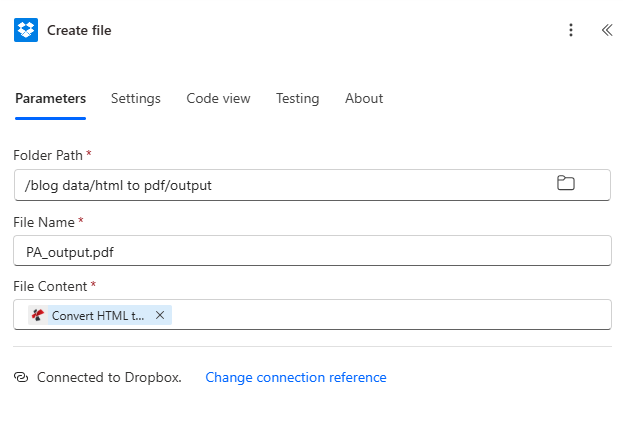
Create file: Folder Path, File Name, File Content mapped from Convert HTML to PDF. The PDF is saved to your chosen folder.
Input and Output: What Goes In, What Comes Out
Here is the HTML input and the generated PDF.
Example HTML input file
Sample HTML input: raw HTML or rendered content. Get file content fetches this file; Convert HTML to PDF preserves CSS, images, and structure in the PDF.
Example PDF output file

Generated PDF: same content as the HTML in PDF form. Use Create file to save to Dropbox, SharePoint, or pass to the next flow action.
Use Cases: When to Use HTML to PDF in Power Automate
Invoices and quotes: Generate HTML from Excel, Dynamics, or a database. Save to a folder; the flow converts to PDF and uploads or emails automatically.
Reports and dashboards: HTML reports from Power BI or templates can be saved in SharePoint. Power Automate converts them to PDF for distribution or archiving.
Certificates and badges: Create HTML certificates from event or training data. Convert to PDF and send via Outlook or store in SharePoint.
Quick Reference: Key Settings
| Action | Setting | Example |
|---|---|---|
| 1. Get file content | File Path | /blog data/html/sample.html |
| 2. Convert HTML to PDF | File Content | From Get file content |
| 3. Create file | File Content | From Convert HTML to PDF |
For full parameter details, see HTML to PDF — Power Automate.
Troubleshooting
Map the actual File Content from Get file content to the Convert HTML to PDF action. Do not use the file path or metadata. The field must contain the binary content.
PDF4me uses HTML File Name to detect the format. Include the .html extension (e.g. sample.html).
In Create file, map File Content from the Convert HTML to PDF action, not from Get file content. The PDF binary comes from PDF4me.
PDF4me Troubleshooting covers 401 (API key), 402 (credits), and more.